Rozoom
Na wystawie w Cogiteonie. Jak działają kopiarki w naszym ciele?

tekst: Gabriela Zielińska
Zacznijmy jednak od początku, od wyjaśnienia jak kodowana jest informacja.
DNA jest cząsteczką zbudowaną z liniowo ułożonych podjednostek nazywanych nukleotydami. To właśnie w kolejności ich ułożenia zapisana jest informacja genetyczna, swoisty „przepis na organizm żywy”. Dlatego podczas kopiowania DNA ważne jest wierne przepisanie sekwencji na nowopowstającą nić. Tylko takie podstępowanie pozwoli zachować tę konkretną informację. I tu właśnie pojawia się doniosła rola polimerazy, czyli enzymu, odpowiedzialnego za wbudowywanie nukleotydów w nowopowstającą nić kwasu nukleinowego.
Skopiuj DNA, nie pomyl się!
Zapraszamy na wystawę do stanowiska
"Jak działają kopiarki w naszym ciele?"
(sala I „Jak się czujesz?”)
Procesy biologiczne zachodzące wewnątrz komórki, w tym kopiowanie DNA (replikacja).
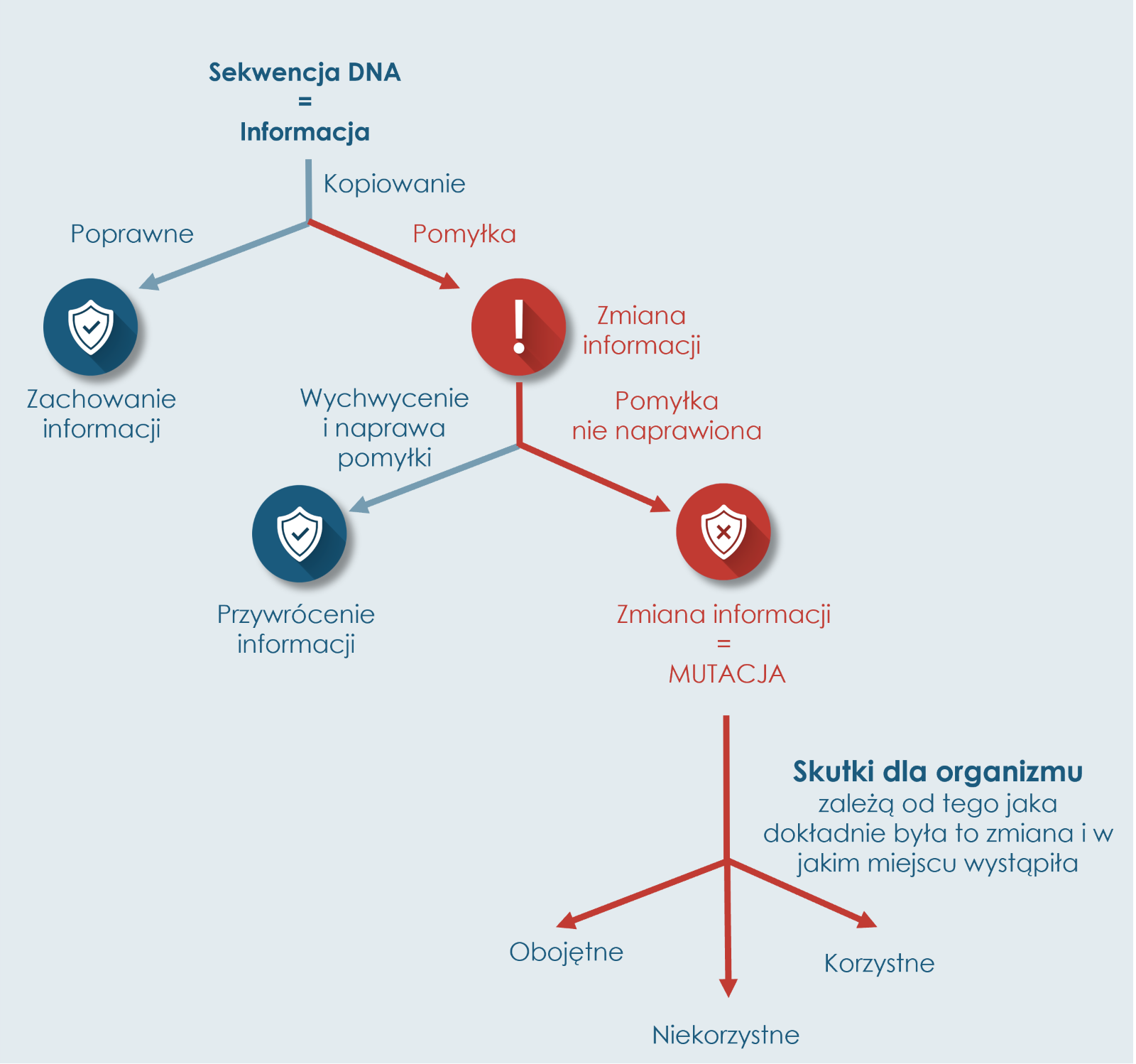
Dlaczego DNA musi być kopiowane?
W DNA zakodowane są informacje na temat budowy i funkcjonowania danego organizmu. Dlatego przed podziałem komórki DNA jest powielane, tak aby powstające w wyniku podziału komórki potomne otrzymały pełny zestaw informacji. Powielanie kwasu nukleinowego (czyli replikacja) jest możliwe dzięki działaniu białka noszącego nazwę polimerazy. Przesuwa się ona wzdłuż jednej nici i traktując ją jako matrycę dobudowuje kolejne podjednostki (nukleotydy) do nowopowstającej nici. Jeśli podczas tego procesu nastąpi pomyłka i komórka ją wychwyci, może naprawić błąd. Natomiast jeśli zmiana, nie zostanie zauważona i naprawiona, pozostaje trwale w sekwencji i nazywana jest mutacją.
Sprawnie działająca „maszyneria komórkowa” powoduje, że do mutacji dochodzi niezwykle rzadko. Szacuje się, że częstotliwość występowania mutacji nie przekracza jednej pomyłki na milion kopiowanych par zasad (10-9 ). [2] Tak wysoka wierność przepisywania sekwencji jest zapewniana przez procesy zachodzące podczas replikacji, jak i już po jej zakończeniu. Po pierwsze polimeraza selektywnie rozpoznaje, jaki nukleotyd powinna wbudować, a jeśli „pomyli się”, może wrócić i usunąć ostatni błędnie wbudowany nukleotyd, zastępując go prawidłowym. Dodatkowo istnieje również szansa późniejszej naprawy niedopasowania DNA – już po replikacji. [3] Czasem jednak pomyłka pozostaje nieusunięta.
Ostatnio dodane w Rozoom
Mutacja. Co to takiego?
W obiegowym języku termin „mutacja” często jest utożsamiany z czymś niekorzystnym dla organizmu. Czy jest tak zawsze? Niekoniecznie.
Mutacja jest zmianą sekwencji genetycznej i jej skutki takiej mogą być różne. Mogą być szkodliwe, ale równie dobrze - korzystne, a w jeszcze innych przypadkach - zupełnie obojętne dla organizmu. Wszystko uzależnione jest od tego, jaka dokładnie zmiana nastąpiła w sekwencji DNA i gdzie była umiejscowiona.
(W dalszej części tekstu wyjaśniony będzie tylko jeden z typów mutacji – mutacja punktowa polegająca na zmianie jednego nukleotydu na inny. Oczywiście istnieje więcej typów mutacji, w tym te obejmujące wstawienie lub opuszczenie nukleotydu(ów), skutkujące przesunięciem tzw. ramki odczytu. Są też mutacje chromosomowe dotyczące całego zestawu chromosomów danego organizmu.)
Mutacja oznacza zmianę informacji
Mała zmiana – wielki efekt
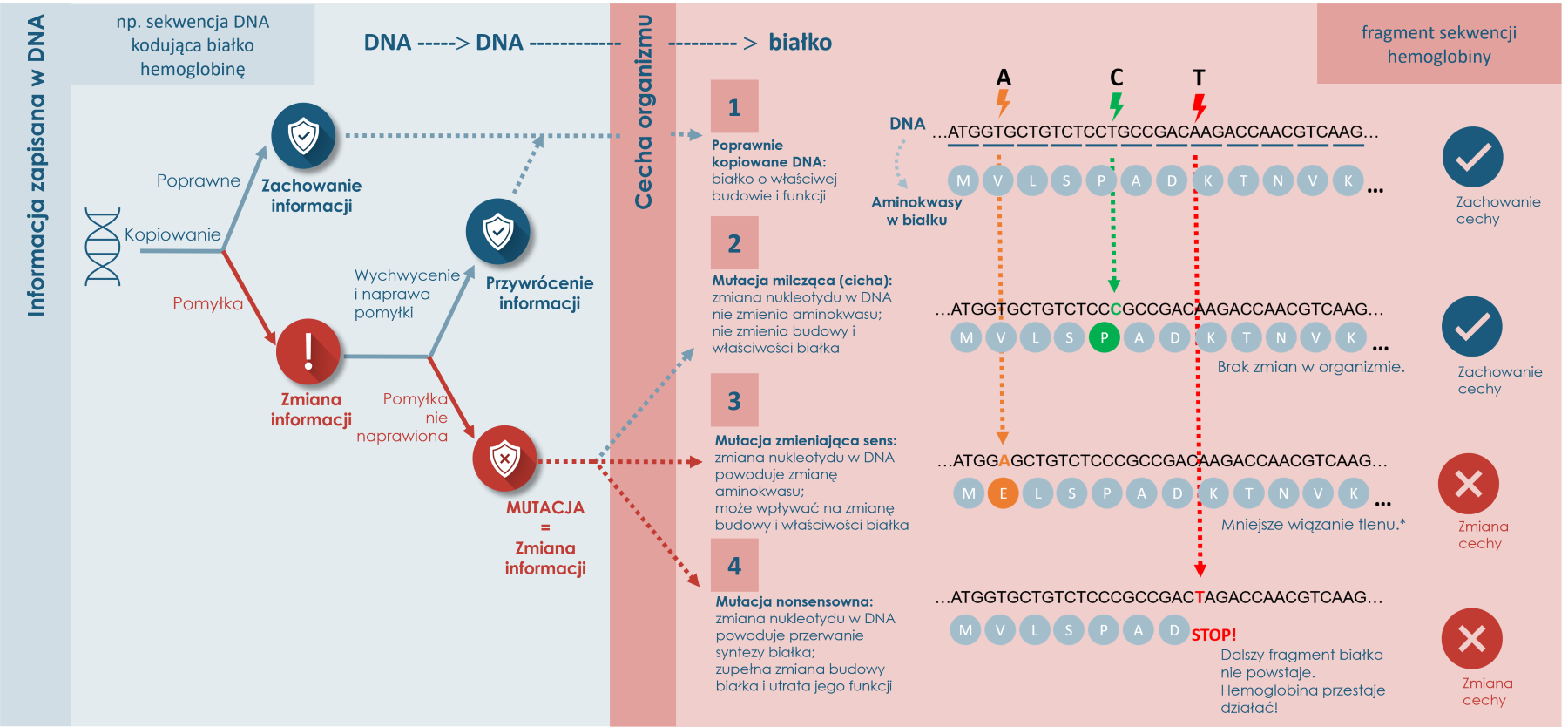
Czasem zmiana choćby jednego nukleotydu może mieć daleko idące konsekwencje. Dlaczego? Przeanalizujmy to zagadnienie posługując się przykładem. Niech będzie nim fragment sekwencji kodującej hemoglobinę, czyli białko występujące w czerwonych krwinkach i odpowiedzialne za wiązanie tlenu i jego transport po organizmie.
Na tym etapie trzeba wspomnieć, że białka powstają zgodnie z informacją zakodowaną w DNA. Proces syntezy (czyli wytwarzania) białka, w którym kolejne aminokwasy dołączane są do powstającego łańcucha białkowego, można porównać do naciągania na nitkę koralików. O tym, które będą to „koraliki” i w jakiej kolejności ułożone, decyduje sekwencja DNA. Każdy z spośród możliwych 20 rożnych aminokwasów – wchodzących w skład danego białka - jest kodowany przez określone trójki nukleotydowe, czyli trzy nukleotydy ułożone kolejno w sekwencji. Trzy nukleotydy są potrzebne, aby zakodować informację o jednym aminokwasie.
Wróćmy jednak do przykładu. Wykorzystamy w nim fragment DNA kodujący początkowy odcinek jednego z łańcuchów białkowych ludzkiej hemoglobiny (łańcucha α). Hemoglobina jest stosunkowo dużym białkiem, dlatego przedstawimy tu jedynie bardzo krótki fragment jednego z łańcuchów białkowych budujących jej cząsteczkę.
Fragment sekwencji nukleotydowej ma postać […] atggtgctgtctcctgccgacaagaccaacgtcaag […] (sekwencja DNA w, której zawarty jest fragment kodujący łańcuch α hemoglobiny ludzkiej dostępna jest w bazie danych National Library of Medicine GenBank: AH005275.2). Oznaczeniami literowymi zapisane są nukleotydy: a – adenina, t – tymina, c – cytozyna, g – guanina.
Na takiej matrycy powinno powstać białko o następującej sekwencji aminokwasów: MVLSPADKTNVK […] (sekwencja aminokwasowa łańcucha α hemoglobiny ludzkiej dostępna jest w bazie UniProt). Oznaczenia literowe symbolizują kolejne aminokwasy.
Czasem zmiana zaledwie jednego nukleotydu zmienia właściwości całego białka.
Grafika przedstawia fragment sekwencji DNA kodującej hemoglobinę. Białko to występuje wewnątrz czerwonych krwinek, wiąże tlen i dostarcza go do wszystkich komórek w organizmie*.
Przypadek 1. Poprawne kopiowanie DNA. W efekcie powstało białko o właściwej sekwencji i właściwościach. Do tej pory wszystko jest idealnie.
Wyobraźmy sobie jednak, że podczas kopiowania tego fragmentu polimeraza wbudowała błędnie jeden nukleotyd. Przeanalizujmy trzy różne możliwości lokalizacji takiego błędu.
Przypadek 2. Na skutek pomyłki polimerazy trójka nukleotydowa CCT kodująca aminokwas prolinę (P) zostaje zastąpiona trójką CCC kodującą… również prolinę (P). Także pomimo zmiany w DNA białko pozostaje niezmienione. Jest to tak zwana mutacja milcząca. Dzieje się tak dlatego, że niektóre z aminokwasów kodowane są przez więcej niż jedną trójkę nukleotydów. Istnieje więc szansa, że pomimo zmiany w DNA nie odzwierciedli się ona w budowie łańcucha aminokwasowego i nie będzie zmian w organizmie. (Reguły przepisywania trójek nukleotydowych na sekwencję aminokwasową >> patrz)
Przypadek 3. Inaczej sprawy będą się miały jeśli trójka nukleotydowa GTG kodująca aminokwas walinę (V) w wyniku mutacji stanie się trójką GAG kodującą kwas glutaminowy (E). Z uwagi na to, że poszczególne aminokwasy różnią się budową chemiczną, wielością, właściwościami to zmiana konkretnego aminokwasu na inny może rzutować na budowę i właściwości całego białka. W tym konkretnym przypadku skutkiem jest zmniejszenie zdolności wiązania tlenu przez tak zmodyfikowaną hemoglobinę.
Przypadek 4. Jeśli trójka AAG kodująca lizynę (K) na skutek mutacji stanie się trójką TAG, zwaną kodonem STOP, synteza białka zostanie przerwana w tym miejscu i dalszy fragment łańcuch hemoglobiny nie powstanie. Skutkiem będzie zupełna zmiana budowy białka i utrata jego funkcji.
W każdym z wymienionych przykładów chodziło o zmianę tylko jednego nukleotydu w długim szeregu sekwencji DNA, a efekty były bardzo odmienne.
Zmiany czasem są potrzebne
Potrzeba zachowania wysokiej dokładności podczas kopiowania informacji genetycznej jest niezbędna dla organizmów żywych. Stąd utrzymywanie tak „wyśrubowanych wyników”, jeśli chodzi o dokładność działania polimerazy. Ale to tylko jedna strona medalu. Zupełne wyeliminowanie mutacji wcale nie byłoby korzystne z biologicznego punktu widzenia. Mutacje wprowadzają naturalną zmienność genetyczną, bez której nie istniałby proces ewolucji. [4], [5] Ale to już temat na kolejną opowieść…
Opracowania danych, infografiki: Gabriela Zielińska
Źródła
* Informacja o wpływie mutacji V2:E2 została zaczerpnięta z: https://pubmed.ncbi.nlm.nih.gov/1618774/
Sekwencja łańcucha α hemoglobiny: https://www.uniprot.org/uniprot/P69905
Sekwencja DNA kodująca łańcuch α hemoglobiny ludzkiej (GenBank: AH005275.2) https://www.ncbi.nlm.nih.gov/nuccore/AH005275.2?report=fasta
---------
[1] Alberts B, Johnson A, Lewis J, et al., Molecular Biology of the Cell. 4th edition., 2002. https://www.ncbi.nlm.nih.gov/books/NBK26850/#__NBK26850_dtls__
[2] McCulloch SD, Kunkel TA,, The fidelity of DNA synthesis by eukaryotic replicative and translesion synthesis polymerases. Cell Res. 2008 Jan;18(1):148-61. doi: 10.1038/cr.2008.4. PMID: 18166979; PMCID: PMC3639319. https://pmc.ncbi.nlm.nih.gov/articles/PMC3639319/
[3] Bębenek A, Ziuzia-Graczyk I. Fidelity of DNA replication-a matter of proofreading. Curr Genet. 2018 Oct;64(5):985-996. doi: 10.1007/s00294-018-0820-1. Epub 2018 Mar 2. PMID: 29500597; PMCID: PMC6153641. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6153641/
[4] Loewe, L. (2008) Genetic mutation. Nature Education 1(1):113 https://www.nature.com/scitable/topicpage/genetic-mutation-1127/
Ostatnio dodane w Rozoom